Построение оракула для генератора кода
В подходе к построению оракула для тестированию генераторов кода в трансляторах, предлагаемом в настоящей работе, реализуется классическая идея сравнения реального результата работы тестируемой системы с ожидаемым результатом [].
В качестве основы для организации тестирования применяется модельный подход, описанный выше в предварительных сведениях. Однако в нашем случае из каждой модельной структуры генератор тестов, кроме собственно входных тестовых данных,ё должен создавать также и ожидаемый эталонный результат трансляции - либо полностью, либо лишь некоторую абстрактную выжимку, своего рода систему показателей, характеризующих ключевые свойства выходных данных транслятора. Для этого генератор тестов должен содержать два разных меппера: один для отображения модельной структуры во входные тестовые данные, другой для ее отображения в эталонную систему показателей выходных данных (см. Рис. 3).
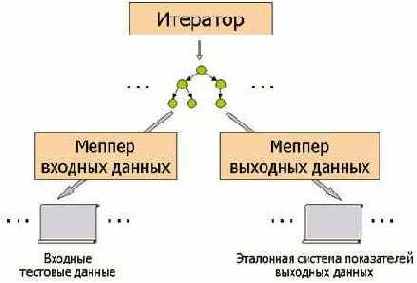
Рис. 3.Схема генерации входных данных и эталонного результата
Для того чтобы было возможно организовать два разных отображения из одной модельной структуры, модель должна строиться с учетом информации не только о входном представлении данных (см. ), но и об их выходном представлении.
В простейшем случае, когда транслятор лишь «переводит» термины входного представления в какие-то соответствующие термины выходного представления, оказывается, что одна и та же модель пригодна для моделирования как входных, так и выходных данных.
В случае же, когда транслятор сначала осуществляет некоторый анализ входных данных, а лишь затем генерирует выходные данные, содержащие результаты проведенного анализа, модель следует обогатить дополнительными элементами, которые представляют собой соответствующие результаты анализа. При этом итерацию модельных структур следует организовать так, чтобы элементы модели, соответствующие «результатам анализа», конструировались непосредственно в процессе итерации - это возможно, например, если организовать итерацию одних элементов модели в зависимости от уже созданного значения другого элемента модели.
Далее мы будем говорить о предложенной схеме генерации тестовых данных в контексте тестирования не всего генератора кода в целом, а лишь некоторого ограниченного его аспекта, поскольку это существенно упрощает модель и облегчает разработку итераторов и мепперов.
Итак, генератор тестов вместе с входными данными генерирует также соответствующую эталонную систему показателей выходных данных.
При использовании такой схемы генерации тестовых данных анализ правильности работы генератора кода в трансляторе состоит в проверке результата работы транслятора на соответствие созданной генератором тестов эталонной системе показателей (см. Рис. 4).

- Анализируется документация на генератор кода в трансляторе, и выделяются те аспекты его работы, которые требуется протестировать;
- Для каждого аспекта выделяются термины и шаблоны входных данных, строится модель;
- В рамках данного аспекта анализируется алгоритм генерации кода, модель обогащается дополнительной информацией для моделирования результатов трансляции;
- Разрабатывается итератор модельных структур;
- Разрабатываются мепперы:
- для отображения модельных структур в предложения входного языка;
- для отображения модельных структур в эталонную систему показателей выходных данных;
- Производится автоматическая генерация тестовых данных:
- входные данные транслятора;
- эталонная система показателей ожидаемых выходных данных транслятора;
- Для каждой сгенерированной пары тестовых данных в автоматическом режиме производится оценка правильности работы генератора кода в трансляторе: входные тестовые данные подаются на вход транслятору, полученный результат работы транслятора сравнивается на соответствие эталонной системе показателей.
